此系列记录我跟随 LearnOpenGL 学习的历程。
LearnOpenGL相关代码
# 高级光照
# Blinn-Phong 模型
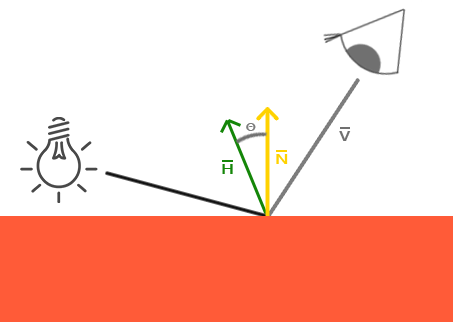
按照 Phong 模型的话,当观察向量和反射向量间的夹角大于 90 度时,点积结果为复数,镜面光分量会变为 0.0。
当计算漫反射光照的时候,我们计算的是光的方向向量与法向量的点积,当夹角大于 90 度的时候,光源会处于被照表面的下方,这个时候光照的漫反射分量的确是为 0.0。
但是在计算镜面高光时,由于我们计算的是视线与反射光线向量的夹角,这个夹角大于 90 度时会直接降低到 0,考虑如下图所示的情况,显然是不合理的。

Blinn-Phong 的解决方案是,不再依赖于反射向量,而是采用了所谓的半程向量 (Halfway Vector),即光线与视线夹角一半方向上的一个单位向量。当半程向量与法线向量越接近时,镜面光分量就越大。这样就保证了不论观察者向哪个方向看,半程向量与表面法线之间的夹角都不会超过 90 度。
获取半程向量的方法很简单,只需要将光线的方向向量和观察向量加到一起,并将结果正规化 (Normalize) 就可以了:
vec3 lightDir = normalize(lightPos - FragPos); | |
vec3 viewDir = normalize(viewPos - FragPos); | |
vec3 halfwayDir = normalize(lightDir + viewDir); | |
float spec = pow(max(dot(normal, halfwayDir), 0.0), shininess); | |
vec3 specular = lightColor * spec; |
风氏模型与 Blinn-Phong 模型有一些细微的差别:半程向量与表面法线的夹角通常会小于观察与反射向量的夹角。所以,如果你想获得和风氏着色类似的效果,就必须在使用 Blinn-Phong 模型时将镜面反光度设置更高一点。通常我们会选择风氏着色时反光度分量的 2 到 4 倍。
# Gamma 校正
为了更适应环境提高生存能力,人类的视觉系统随着进化出了一个特性:黑暗环境下的辨识能力要强于明亮环境,这可能有助于我们及时发现黑暗中隐藏的危险,因此,人类的黑色的感知能力要远高于对白色的感知。

第一行是人眼所感知到的正常的灰阶,亮度要增加一倍(比如从 0.1 到 0.2)你才会感觉比原来变亮了一倍,然而,当我们谈论光的物理亮度,比如光源发射光子的数量的时候,底部(第二行)的灰阶显示出的才是物理世界真实的亮度。物理亮度和感知亮度的区别在于,物理亮度基于光子数量,感知亮度基于人的感觉,比如第二个灰阶里亮度 0.1 的光子数量是 0.2 的二分之一。
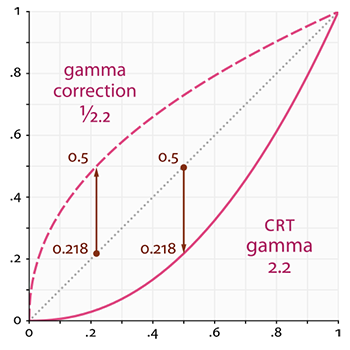
其中横轴代表着自然界线性增长的亮度,竖轴表示人实际感受到均匀亮度,红色的虚线就是 Gamma 矫正曲线(gamma 默认值 2.2,也是一个经验值),红色的实线是显示器显示的颜色(为了迎合我们的主观灰阶感受)
为什么计算机显示的图象颜色要用校正后的主观灰阶感受,而不是自然亮度,其实主要原因是因为计算机精度问题,因为计算机能表示的颜色数量的有限的,人类对黑暗更为敏感,因此要在黑暗片段上使用更高的精度。
例如,如果我们仅能储存 5 位灰度图像,即有 32 种不同的灰度,从纯黑到纯白,如果我们用物理线性灰度来编码表示从 0-1 的灰度渐变,则得到的灰色渐变图如图所示。
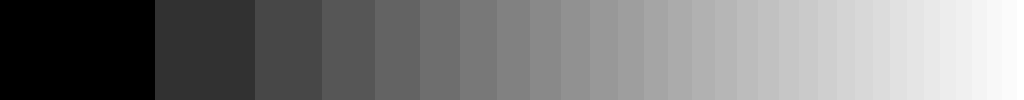
能感觉到左侧的条带跨度比右侧的条带跨度更宽,渐变更不均匀,这是由于我们人眼主观感受决定,为了对齐人类感知的灰度渐变,我们将左边灰度的条带拉宽,右边亮部的条带压扁,这样看起来的灰度过渡更加自然。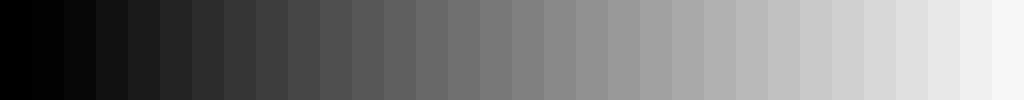
所以我们会将颜色进行 gamma 矫正,对亮度低的片段上使用更高精度,由此编码得到的灰色渐变图如上图所示,明显感觉到更加自然。
# OpenGL 中的 Gamma 校正
有两种在你的场景中应用 gamma 校正的方式:
- 使用 OpenGL 内建的 sRGB 帧缓冲。
- 自己在像素着色器中进行 gamma 校正。
第一个选项也许是最简单的方式,但是也会丧失一些控制权。开启 GL_FRAMEBUFFER_SRGB,可以告诉 OpenGL 每个后续的绘制命令里,在颜色储存到颜色缓冲之前先校正 sRGB 颜色。sRGB 这个颜色空间大致对应于 gamma2.2,它也是大多数设备的一个标准。开启 GL_FRAMEBUFFER_SRGB 以后,每次像素着色器运行后续帧缓冲,OpenGL 将自动执行 gamma 校正,包括默认帧缓冲。
glEnable(GL_FRAMEBUFFER_SRGB);
第二种方法需要更多的工作,但也让我们完全控制伽马操作。我们在每个相关的像素着色器运行结束时应用伽玛校正,因此最终的颜色在发送到显示器之前结束伽玛校正。
void main() | |
{ | |
// 在线性空间做炫酷的光照效果 | |
[...] | |
// 应用伽马矫正 | |
float gamma = 2.2; | |
fragColor.rgb = pow(fragColor.rgb, vec3(1.0/gamma)); | |
} |
为了保持一致性,你必须对每个有助于最终输出的片段着色器应用伽玛校正。如果你有多个对象的十几个片段着色器,你必须为每个着色器添加伽马校正代码。
一个更简单的解决方案是在你的渲染循环中引入一个后处理阶段,并在后处理的四边形上应用伽马校正作为最后一步,这样你只需要做一次伽马矫正即可。
# 纹理中的 Gamma 校正
所有的光照计算(之前的漫反射和镜面反射等)都一定是在线性空间计算的,这也意味着,如果你在计算物体最终颜色之前就进行过了 Gamma 矫正(进入了非线性空间),那么这个计算结果肯定就不对了(特别是颜色之间的混合),毕竟次方运算根本不是线性运算,更不可能遵循交换律,遗憾的是,这种错误在很多地方都有。
很多纹理,都已经进行过了 gamma 矫正!除非能确保纹理制作者是在线性空间中进行创作的,然而事实上就是:大多数纹理制作者并不知道什么是 gamma 校正,它们都是在 sRGB 空间中进行创作的(上面提过,sRGB 空间定义的 gamma 接近于 2.2,不属于线性空间)。
这样的话,对于 sRGB 空间制作的纹理,我们就必须要在进行光照计算前进行重校,也就是拉回线性空间,不过还好,如果在 glTexImage2D () 时指定纹理格式为 GL_SRGB 或 GL_SRGB_ALPHA,那么 openGL 内部就会自动帮你重校。
在指定纹理格式前一定要确定纹理类型,不是所有纹理都进行过 gamma 矫正的,举个例子:对于专业的美术,制作 specular 贴图和法线贴图几乎肯定是在线性空间中的,这主要是为了确定更准确的光照参数。
# 效果图
开启 gamma 校正 / 关闭 gamma 校正


# 阴影
阴影是光线被阻挡的结果,当一个光源的光线由于其他物体的阻挡不能够达到一个物体的表面的时候,那么这个物体就在阴影中了,有阴影的时候你能更容易地区分出物体之间的位置关系。
理论上阴影无处不在,但是想要渲染出很好的阴影效果,并不是一件特别容易的事,目前实时渲染领域还没找到一种完美的阴影算法,尽管有不少近似阴影技术,但它们都有自己的弱点和不足。视频游戏中较多使用的一种技术是阴影贴图(shadow mapping),效果不错,而且相对容易实现。(在 Games202 中对阴影也有更进一步的讨论)
# 阴影贴图
阴影贴图 (Shadow Mapping) 背后的思路非常简单:我们以光的位置为视角进行渲染,我们能看到的东西都将被点亮,看不见的一定是在阴影之中了。
如果我们可以计算出来场景中的物体相对于光源的深度值来表示相对于光源的距离,储存为一张深度贴图。之后从观察者角度渲染场景,我们可以将在点 P 处所需渲染的片段,变换到光源的坐标空间里,通过比较变换后点 P 的 z 值以及深度贴图中从光的视角中最近的可见深度,如果 P 的 z 值更大,则说明 P 被遮挡,如下图所示。
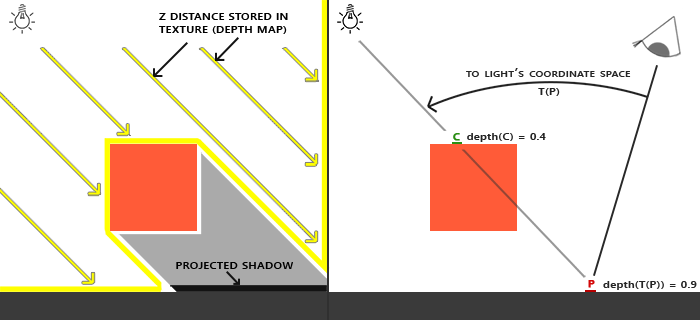
而如何获取深度贴图呢,在深度测试一节中,我们可以得知在深度缓冲里的一个值是摄像机视角下,对应于一个片段的一个 0 到 1 之间的深度值。那我们以光源为观察点渲染场景,并将深度值的结果储存到纹理中,就能得到所需要的深度贴图,也叫阴影贴图。
不同的光源需要计算的深度贴图不一样。对于平行光来说,采取正交投影;对于聚光源来说,采取透视投影;而点光源比较特殊,点光源是 360° 全视角,所以计算深度贴图需要计算立方体深度贴图,同时应该采用透视投影。
总的来说,阴影映射由两个步骤组成:首先,我们渲染深度贴图,然后我们像往常一样渲染场景,使用生成的深度贴图来计算片段是否在阴影之中。
# OpenGL 中的深度贴图
# 平行光
平行光与点光源不同,它没有具体的位置,而是用方向来表示光线的照射方向。但在生成深度贴图时,需要定义一个 "虚拟" 的光源位置(即视点),这个位置通常选择在场景的包围盒(Bounding Box)之外,确保能覆盖整个场景。
第一步我们需要生成一张深度贴图 (Depth Map)。深度贴图是从光的透视图里渲染的深度纹理,用它计算阴影。因为我们需要将场景的渲染结果储存到一个纹理中,我们将再次需要帧缓冲。
首先,我们要为渲染的深度贴图创建一个帧缓冲对象。然后,创建一个 2D 纹理,提供给帧缓冲的深度缓冲使用。因为只需要关心深度值,所以可以把纹理格式指定为 GL_DEPTH_COMPONENT,并通过 glDrawBuffer (GL_NONE) 和 glReadBuffer (GL_NONE) 来通知 OpenGL 不对颜色缓冲进行读写。
// 创建帧缓冲对象 fbo | |
GLuint depthMapFBO; | |
glGenFramebuffers(1, &depthMapFBO); | |
// 创建一个 2D 纹理,提供给帧缓冲的深度缓冲使用 | |
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024; | |
GLuint depthMap; | |
glGenTextures(1, &depthMap); | |
glBindTexture(GL_TEXTURE_2D, depthMap); | |
glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, | |
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL); | |
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); | |
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST); | |
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); | |
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT); | |
// 把我们把生成的深度纹理作为帧缓冲的深度缓冲 | |
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); | |
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, GL_TEXTURE_2D, depthMap, 0); | |
glDrawBuffer(GL_NONE); | |
glReadBuffer(GL_NONE); | |
glBindFramebuffer(GL_FRAMEBUFFER, 0); |
阴影贴图一般固定贴图分辨率大小,并且阴影贴图经常和我们原来渲染的场景(通常是窗口分辨率)有着不同的分辨率,所以在每次渲染之前需要改变视口大小,调用 glViewport。即渲染得到深度贴图之前调用:
合理配置将深度值渲染到纹理的帧缓冲后,我们就可以开始第一步了:生成深度贴图。两个步骤的完整的渲染阶段,代码过程如下:
// 1. 首选渲染深度贴图 | |
glViewport(0, 0, SHADOW_WIDTH, SHADOW_HEIGHT); // 视口更换到阴影贴图大小 | |
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); | |
glClear(GL_DEPTH_BUFFER_BIT); | |
ConfigureShaderAndMatrices(); | |
RenderScene(); | |
glBindFramebuffer(GL_FRAMEBUFFER, 0); | |
// 2. 像往常一样渲染场景,但这次使用深度贴图 | |
glViewport(0, 0, SCR_WIDTH, SCR_HEIGHT); // 视口更换到往常一样的大小 | |
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); | |
ConfigureShaderAndMatrices(); | |
glBindTexture(GL_TEXTURE_2D, depthMap); | |
RenderScene(); |
ConfigureShaderAndMatrices () 函数则为每个物体设置合适的投影、视图、模型矩阵。在第一个步骤中,我们以光源为观察点,计算光空间的投影和观察矩阵,相乘得到的称为光源的空间矩阵 T。
这里由于计算的是平行光,我们需要选取一个虚拟的光源位置,一般这个虚拟的光源位置选择在场景的包围盒(Bounding Box)之外,确保能覆盖整个场景。同时使用正交投影矩阵(glm::ortho)定义一个立方体区域(视景体),确保包含所有需要投射阴影的物体。
// 计算光空间的投影与观察矩阵。 | |
GLfloat near_plane = 1.0f, far_plane = 7.5f; | |
glm::mat4 lightProjection = glm::ortho(-10.0f, 10.0f, -10.0f, 10.0f, near_plane, far_plane); | |
glm::mat4 lightView = glm::lookAt(glm::vec3(-2.0f, 4.0f, -1.0f), glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3(0.0f, 1.0f, 0.0f)); | |
glm::mat4 lightSpaceMatrix = lightProjection * lightView; | |
// 传入光空间矩阵并渲染 | |
simpleDepthShader.Use(); | |
glUniformMatrix4fv(lightSpaceMatrixLocation, 1, GL_FALSE, glm::value_ptr(lightSpaceMatrix)); | |
RenderScene(simpleDepthShader); |
当我们以光的透视图进行场景渲染的时候,我们会用一个比较简单的着色器,这个着色器除了把顶点变换到光空间以外,不会做得更多了。
// 顶点着色器,变换到光空间 | |
#version 330 core | |
layout (location = 0) in vec3 position; | |
uniform mat4 lightSpaceMatrix; | |
uniform mat4 model; | |
void main() | |
{ | |
gl_Position = lightSpaceMatrix * model * vec4(position, 1.0f); | |
} | |
// 片段着色器,为空,因为只需要深度值 | |
#version 330 core | |
void main() | |
{ | |
// gl_FragDepth = gl_FragCoord.z; | |
} |
正确生成深度贴图后,我们就可以开始生成阴影了。在顶点着色器中,进行光空间的变换。
#version 330 core | |
layout (location = 0) in vec3 position; | |
layout (location = 1) in vec3 normal; | |
layout (location = 2) in vec2 texCoords; | |
out vec2 TexCoords; | |
out VS_OUT { | |
vec3 FragPos; | |
vec3 Normal; | |
vec2 TexCoords; | |
vec4 FragPosLightSpace; | |
} vs_out; | |
uniform mat4 projection; | |
uniform mat4 view; | |
uniform mat4 model; | |
uniform mat4 lightSpaceMatrix; | |
void main() | |
{ | |
gl_Position = projection * view * model * vec4(position, 1.0f); | |
vs_out.FragPos = vec3(model * vec4(position, 1.0)); | |
vs_out.Normal = transpose(inverse(mat3(model))) * normal; | |
vs_out.TexCoords = texCoords; | |
vs_out.FragPosLightSpace = lightSpaceMatrix * vec4(vs_out.FragPos, 1.0); | |
} |
在片段着色器中,我们检查片段是否在阴影中。
首先把光空间片段位置转换为裁切空间的标准化设备坐标。当我们在顶点着色器输出一个裁切空间顶点位置到 gl_Position 时,OpenGL 自动进行一个透视除法,将裁切空间坐标的范围 - w 到 w 转为 - 1 到 1,这要将 x、y、z 元素除以向量的 w 元素来实现。由于裁切空间的 FragPosLightSpace 并不会通过 gl_Position 传到片段着色器里,我们必须自己做透视除法。
因为来自深度贴图的深度在 0 到 1 的范围,而变换后的光空间坐标范围在 [-1,1] 之间,并且在采样深度贴图的时候,xy 分裂也要变换到 [0,1],所以我们还要再做一个变换。
#version 330 core | |
out vec4 FragColor; | |
in VS_OUT { | |
vec3 FragPos; | |
vec3 Normal; | |
vec2 TexCoords; | |
vec4 FragPosLightSpace; | |
} fs_in; | |
uniform sampler2D diffuseTexture; | |
uniform sampler2D shadowMap; | |
uniform vec3 lightPos; | |
uniform vec3 viewPos; | |
float ShadowCalculation(vec4 fragPosLightSpace) | |
{ | |
// 执行透视除法 | |
vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w; | |
// 变换到 [0,1] 的范围 | |
projCoords = projCoords * 0.5 + 0.5; | |
// 取得最近点的深度 (使用 [0,1] 范围下的 fragPosLight 当坐标) | |
float closestDepth = texture(shadowMap, projCoords.xy).r; | |
// 取得当前片段在光源视角下的深度 | |
float currentDepth = projCoords.z; | |
// 检查当前片段是否在阴影中 | |
float shadow = currentDepth > closestDepth ? 1.0 : 0.0; | |
return shadow; | |
} | |
void main() | |
{ | |
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb; | |
vec3 normal = normalize(fs_in.Normal); | |
vec3 lightColor = vec3(1.0); | |
// Ambient | |
vec3 ambient = 0.15 * color; | |
// Diffuse | |
vec3 lightDir = normalize(lightPos - fs_in.FragPos); | |
float diff = max(dot(lightDir, normal), 0.0); | |
vec3 diffuse = diff * lightColor; | |
// Specular | |
vec3 viewDir = normalize(viewPos - fs_in.FragPos); | |
vec3 reflectDir = reflect(-lightDir, normal); | |
float spec = 0.0; | |
vec3 halfwayDir = normalize(lightDir + viewDir); | |
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0); | |
vec3 specular = spec * lightColor; | |
// 计算阴影 | |
float shadow = ShadowCalculation(fs_in.FragPosLightSpace); | |
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color; | |
FragColor = vec4(lighting, 1.0f); | |
} |
# 点光源
点光源的阴影技术也叫万向阴影贴图(omnidirectional shadow maps)技术。
算法和定向阴影映射差不多:我们从光的透视图生成一个深度贴图,基于当前 fragment 位置来对深度贴图采样,然后用储存的深度值和每个 fragment 进行对比,看看它是否在阴影中。定向阴影映射和万向阴影映射的主要不同在于深度贴图的使用上。
对于点光源来说,它对四周都发出光线,所以我们要采用立方体贴图 CubeMap 贴图来储存深度值,采样深度值时用方向向量进行采样即可。我们可以渲染场景 6 次,每次一个面来创建这个立方体的深度贴图,也可以利用几何着色器来通过一次渲染过程建立深度立方体贴图。
使用几何着色器来生成深度贴图不会一定比每个面渲染场景 6 次更快。使用几何着色器有它自己的性能局限,在第一个阶段使用它可能获得更好的性能表现。这取决于环境的类型,以及特定的显卡驱动等等。
// 创造立方体贴图 | |
GLuint depthCubemap; | |
glGenTextures(1, &depthCubemap); | |
//CubeMap 的宽高要相等。 | |
const GLuint SHADOW_WIDTH = 1024, SHADOW_HEIGHT = 1024; | |
glBindTexture(GL_TEXTURE_CUBE_MAP, depthCubemap); | |
for (GLuint i = 0; i < 6; ++i) | |
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_DEPTH_COMPONENT, | |
SHADOW_WIDTH, SHADOW_HEIGHT, 0, GL_DEPTH_COMPONENT, GL_FLOAT, NULL); | |
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_NEAREST); | |
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_NEAREST); | |
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE); | |
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE); | |
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE); | |
// 绑定到帧缓冲对象上 | |
glBindFramebuffer(GL_FRAMEBUFFER, depthMapFBO); | |
glFramebufferTexture(GL_FRAMEBUFFER, GL_DEPTH_ATTACHMENT, depthCubemap, 0); | |
glDrawBuffer(GL_NONE); | |
glReadBuffer(GL_NONE); | |
glBindFramebuffer(GL_FRAMEBUFFER, 0); |
万向阴影贴图有两个渲染阶段:首先我们生成深度贴图,然后我们正常使用深度贴图渲染,在场景中创建阴影。这个过程和默认的阴影映射一样,尽管这次我们渲染和使用的是一个立方体贴图深度纹理,而不是 2D 深度纹理。在我们实际开始从光的视角的所有方向渲染场景之前,我们先得计算出合适的变换矩阵。
对于点光源来说,每个面都需要一个变换矩阵 T。每个光空间的变换矩阵包含投影和视图矩阵,每个光空间的投影矩阵是一样的,但是投影矩阵的视野 fov 需要设置为 90 度,这样才能保证视野足够大到可以合适地填满立方体贴图的一个面,立方体贴图的所有面都能与其他面在边缘对齐。每个面的视图矩阵是不一样的,每个都按顺序注视着立方体贴图的的一个方向:右、左、上、下、近、远。之后把这些变换矩阵发送到着色器渲染到立方体贴图里。
GLfloat aspect = (GLfloat)SHADOW_WIDTH/(GLfloat)SHADOW_HEIGHT; | |
GLfloat near = 1.0f; | |
GLfloat far = 25.0f; | |
glm::mat4 shadowProj = glm::perspective(glm::radians(90.0f), aspect, near, far); | |
std::vector<glm::mat4> shadowTransforms; | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0))); | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(-1.0,0.0,0.0), glm::vec3(0.0,-1.0,0.0))); | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,1.0,0.0), glm::vec3(0.0,0.0,1.0))); | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,-1.0,0.0), glm::vec3(0.0,0.0,-1.0))); | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,1.0), glm::vec3(0.0,-1.0,0.0))); | |
shadowTransforms.push_back(shadowProj * | |
glm::lookAt(lightPos, lightPos + glm::vec3(0.0,0.0,-1.0), glm::vec3(0.0,-1.0,0.0))); |
这次几何着色器是负责将所有世界空间的顶点变换到 6 个不同的光空间的着色器。因此顶点着色器简单地将顶点变换到世界空间,然后直接发送到几何着色器。
// 顶点着色器 | |
#version 330 core | |
layout (location = 0) in vec3 position; | |
uniform mat4 model; | |
void main() | |
{ | |
gl_Position = model * vec4(position, 1.0); | |
} |
对于几何着色器来说,有一个内建变量叫做 gl_Layer,它指定发散出基本图形送到立方体贴图的哪个面,当我们更新这个变量就能控制每个基本图形将渲染到立方体贴图的哪一个面。
// 几何着色器 | |
#version 330 core | |
layout (triangles) in; | |
layout (triangle_strip, max_vertices=18) out; | |
uniform mat4 shadowMatrices[6]; | |
out vec4 FragPos; // FragPos from GS (output per emitvertex) | |
void main() | |
{ | |
for(int face = 0; face < 6; ++face) | |
{ | |
gl_Layer = face; // built-in variable that specifies to which face we render. | |
for(int i = 0; i < 3; ++i) // for each triangle's vertices | |
{ | |
FragPos = gl_in[i].gl_Position; | |
gl_Position = shadowMatrices[face] * FragPos; | |
EmitVertex(); | |
} | |
EndPrimitive(); | |
} | |
} |
对于片段着色器来说,这次我们将自己计算深度,为每个片段与光源之间的线性距离。相比于定向光来说,因为定向光的光源位置是虚拟的,深度只取决于 z 值。而点光源需要计算径向距离。
更进一步的讨论,因为投影矩阵的缘故,坐标空间是非线性的,这会导致近处物体精度更高,远处物体精度更低,我们可以将从非线性的空间变换回来,储存线性的深度值。(暂未实现)
#version 330 core | |
in vec4 FragPos; | |
uniform vec3 lightPos; | |
uniform float far_plane; | |
void main() | |
{ | |
// 计算距离 | |
float lightDistance = length(FragPos.xyz - lightPos); | |
// 通过除以远平面值来映射到 [0,1] 范围内。 | |
lightDistance = lightDistance / far_plane; | |
// 更改深度值。 | |
gl_FragDepth = lightDistance; | |
} |
创建完深度立方体贴图后,我们就可以进行渲染阴影了。和平行光的差别不大,只是现在我们需要引入光的视锥的远平面值,同时采样时利用方向向量采样,采样后利用远平面值将采样得到的深度值重新变换回 [0,far_plane] 的范围,再进行比较:
float ShadowCalculation(vec3 fragPos) | |
{ | |
vec3 fragToLight = fragPos - lightPos; | |
float closestDepth = texture(depthMap, fragToLight).r; | |
closestDepth *= far_plane; | |
float currentDepth = length(fragToLight); | |
float shadow = currentDepth > closestDepth ? 1.0 : 0.0; | |
return shadow; | |
} |
# 阴影失真
按照如上做法做完后,会发现出现明显的阴影失真 (Shadow Acne) 现象,地板四边形渲染出很大一块交替黑线。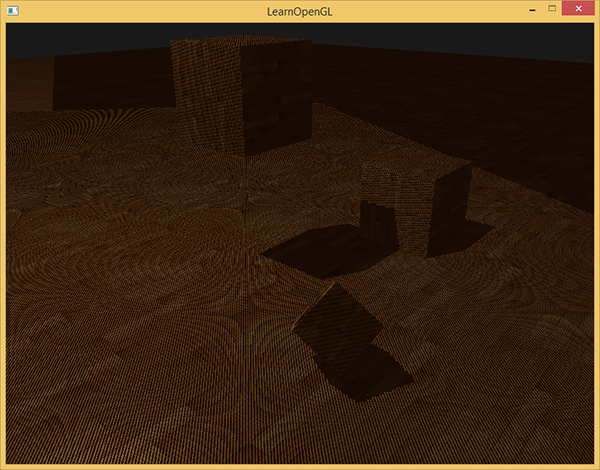
阴影失真产生的原因是因为阴影贴图的分辨率不足。
如图所示,上图的黄点与蓝点都采样到 shadow map 中的同一个值 depth=3,但是蓝点的 z>3,那么蓝点便被认为在阴影里,黄点的 z<3, 黄点就不在阴影里,于是就出现了阴影条纹。
LearnOpenGL 中提出利用阴影偏移(shadow bias)的技巧来解决这个问题,也就是让蓝点的 z 值减去一个较小的距离 bias,这样就不在阴影里了,条纹就消失了。
float bias = 0.005 | |
float shadow = z - bias < depth ? 0.0 : 1.0; |
一个 0.005 的偏移就能帮到很大的忙,但是有些表面坡度很大,仍然会产生阴影失真。有一个更加可靠的办法能够根据表面朝向光线的角度更改偏移量,使用点乘:
float bias = max(0.05 * (1.0 - dot(normal, lightDir)), 0.005); |
但是这个阴影偏移 (shadow bias) 会产生悬浮 (Peter Panning) 的问题,箱子画圈部分的影子没有了。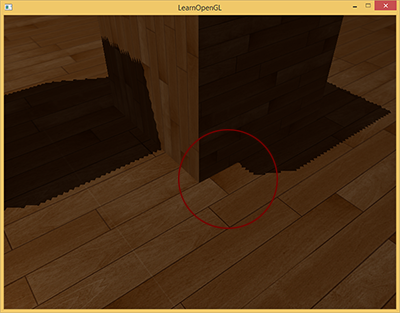
因为 bias 会导致一些原本在阴影部分片段被判断为不在阴影部分里,如下图所示,如果 bias 足够大,会使本应在阴影里的蓝点判断为不在阴影里。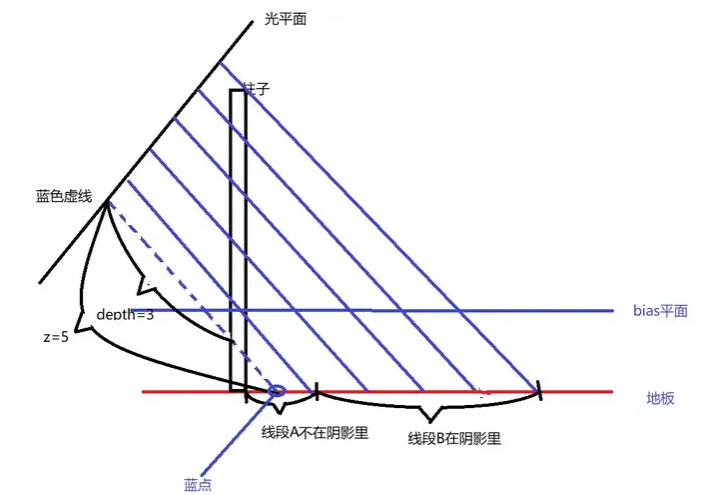
在 LearnOpenGL 中认为,在渲染深度贴图时使用正面剔除(front face culling)可以解决阴影悬浮现象,但这是不正确的。
当开启正面剔除,不使用 bias 时,蓝色线深度值为柱子的实线部分交叉点,会在实线上产生条纹,由于在柱子内部,一般看不到,所以就解决了黑色条纹的问题。但是当物体紧贴地面的时候,由于精度问题会出现漏光 (成因与之前阴影失真原因一致,但是好多了)。对于地板,如果地板顶点编号为顺时针(被认为是背面),则深度贴图依旧在地板上,便依旧会产生阴影失真的条纹现象,如果正确编号则不会。
而如果开启正面剔除,并引入 bias,由于正面剔除导致储存的深度值更加远离光源,并且加上 bias,会产生更加严重的悬浮问题。所以 bias 和面剔除都是用来解决 Shadow Acne 的,并且两者最好不要混用。
# 光锥外采样
阴影贴图还有一个限制,就是光的视锥不可见的区域一律被认为是处于阴影中,不管它真的处于阴影之中。
为了解决这个问题,首先我们需要将深度贴图的纹理环绕选项设置为 GL_CLAMP_TO_BORDER,在所有超出深度贴图的坐标的深度范围是 1.0,这样超出的坐标将永远不在阴影之中。
但是还有一个问题,当一个点比光的远平面还要远时,它的投影坐标的 z 坐标大于 1.0,这种情况下,GL_CLAMP_TO_BORDER 环绕方式不起作用,因为我们把坐标的 z 元素和深度贴图的值进行了对比;它总是为大于 1.0 的 z 返回 true。解决这个问题也很简单,只要投影向量的 z 坐标大于 1.0,我们就把 shadow 的值强制设为 0.0:
float ShadowCalculation(vec4 fragPosLightSpace) | |
{ | |
[...] | |
if(projCoords.z > 1.0) | |
shadow = 0.0; | |
return shadow; | |
} |
# PCF(更加柔和的阴影)
因为深度贴图有一个固定的分辨率,多个片段对应于一个纹理像素。结果就是多个片段会从深度贴图的同一个深度值进行采样,这几个片段便得到的是同一个阴影,这就会产生锯齿边。
最简单粗暴的方法就是通过增加深度贴图的分辨率的方式来降低锯齿块,或者让光的视锥接近场景。
还有一种方法叫做 PCF(percentage-closer filtering),产生更加柔和的阴影边缘。核心思想是从深度贴图中多次采样,每一次采样的纹理坐标都稍有不同。每个独立的样本可能在也可能不再阴影中。所有的次生结果接着结合在一起,进行平均化,我们就得到了柔和阴影。
对于定向光源,我们对纹理像素的四周做深度贴图采样,然后把结果平均起来:
float shadow = 0.0; | |
vec2 texelSize = 1.0 / textureSize(shadowMap, 0); | |
for(int x = -1; x <= 1; ++x) | |
{ | |
for(int y = -1; y <= 1; ++y) | |
{ | |
float pcfDepth = texture(shadowMap, projCoords.xy + vec2(x, y) * texelSize).r; | |
shadow += currentDepth - bias > pcfDepth ? 1.0 : 0.0; | |
} | |
} | |
shadow /= 9.0; |
但是对于点光源来说,加入第三个维度会使得采样样本太多了,大多数这些采样都是多余的,与其在原始方向向量附近处采样,理想的应该在采样方向向量的垂直方向进行采样。但是指出哪一个子方向是多余的是很困难的。
所以我们用一个偏移量方向数组,它们差不多都是分开的,每一个指向完全不同的方向,剔除彼此接近的那些子方向 (彼此之间夹角大于 90 度)。下面就是一个有着 20 个偏移方向的数组。
vec3 sampleOffsetDirections[20] = vec3[] | |
( | |
vec3( 1, 1, 1), vec3( 1, -1, 1), vec3(-1, -1, 1), vec3(-1, 1, 1), | |
vec3( 1, 1, -1), vec3( 1, -1, -1), vec3(-1, -1, -1), vec3(-1, 1, -1), | |
vec3( 1, 1, 0), vec3( 1, -1, 0), vec3(-1, -1, 0), vec3(-1, 1, 0), | |
vec3( 1, 0, 1), vec3(-1, 0, 1), vec3( 1, 0, -1), vec3(-1, 0, -1), | |
vec3( 0, 1, 1), vec3( 0, -1, 1), vec3( 0, -1, -1), vec3( 0, 1, -1) | |
); | |
float shadow = 0.0; | |
float bias = 0.15; | |
int samples = 20; | |
float viewDistance = length(viewPos - fragPos); | |
float diskRadius = 0.05; | |
for(int i = 0; i < samples; ++i) | |
{ | |
float closestDepth = texture(depthMap, fragToLight + sampleOffsetDirections[i] * diskRadius).r; | |
closestDepth *= far_plane; // Undo mapping [0;1] | |
if(currentDepth - bias > closestDepth) | |
shadow += 1.0; | |
} | |
shadow /= float(samples); |
同时还有一个小技巧,我们可以基于观察者里一个 fragment 的距离来改变 diskRadius;这样我们就能根据观察者的距离来增加偏移半径了,当距离更远的时候阴影更柔和,更近了就更锐利。
float diskRadius = (1.0 + (viewDistance / far_plane)) / 25.0; |
# 法线贴图
在 3D 场景中,多边形物体通常由大量三角形组成。虽然纹理能增加表面细节,但近看仍会暴露几何体本身的平坦特性。现实世界的物体表面充满微观起伏(如砖墙的接缝、凹陷),传统光照无法呈现这些细节。
法线贴图(Normal Mapping) 通过为每个片段(Fragment) 提供独立法线向量,欺骗光照系统产生表面凹凸的幻觉:
在使用法线贴图之前你不得不使用相当多的顶点才能表现出一个更精细的网格,但使用了法线贴图我们可以使用更少的顶点表现出同样丰富的细节。高精度网格和使用法线贴图的低精度网格几乎区分不出来,所以是一个将高精度多边形转换为低精度多边形而不失细节的重要工具。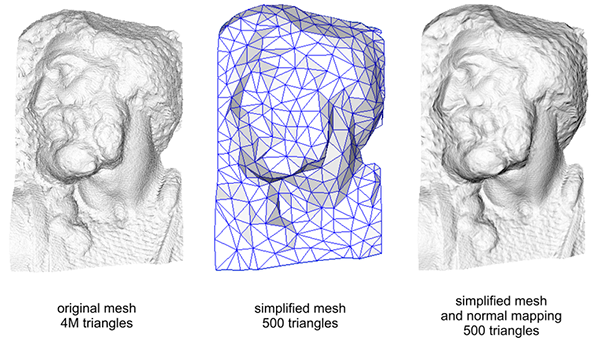
为使法线贴图工作,我们需要为每个 fragment 提供一个法线。像 diffuse 贴图和 specular 贴图一样,我们可以使用一个 2D 纹理来储存法线数据。2D 纹理不仅可以储存颜色和光照数据,还可以储存法线向量。这样我们可以从 2D 纹理中采样得到特定纹理的法线向量。法线向量的范围在 - 1 到 1 之间,所以我们先要将其映射到 0 到 1 的范围:
vec3 rgb_normal = normal * 0.5 + 0.5; // 从 [-1,1] 转换至 [0,1] |
在定义法线贴图时,我们认为每个 fragment 朝向屏幕外方(即表面法线朝向正 z 轴的方向),所以法线贴图一般呈蓝色调,因为多数法线指向 z 轴 (想象一个凹凸不平的表面面对你,每个片段的法向量虽然也向其他方向轻微偏移,但是大体上还是更朝向 z 轴的)。如下图所示:
比如上图,在每个砖块的顶部,颜色倾向于偏绿,这是因为砖块的顶部的法线偏向于指向正 y 轴方向(0, 1, 0),这样它就是绿色的了。
如果我们最终要渲染的片段的表面法线确实是朝向正 z 轴的,那么法线贴图将会工作的很好。但是如果表面法线指向正 y 方向的平面上,那光照将会不对。
# 切线空间
所以这个时候需要引入切线空间 (Tangent Space) 的概念。切线空间是定义在片段上的局部坐标系,我们的法线向量便是定义在这个坐标系上的。在线性代数中,我们只需要将一个坐标系的基向量在另一个坐标系表示,便可以求出这个间坐标系中的向量在另一个坐标系中的表示。也就是我们只需要知道片段在世界空间中移动旋转等变换之后的基向量如何在世界空间坐标系表示,就能把法线向量变换到世界空间坐标系中。
我们定义切线空间的基向量为:切线 (Tagent) 向量、副切线 (Bitangent) 向量、顶点法线 (Normal) 向量,同时我们定义法线贴图的切线和副切线与纹理坐标的两个方向对齐。把他们组合到一起的矩阵叫 TBN 矩阵,从法线贴图采样得到的法线向量左乘 TBN 矩阵便能变换到世界空间坐标系中。
表面法线向量是我们已知的,同时我们还知道片段三角形的三个顶点坐标与对应的纹理坐标,那我们还需要求出切线向量和副切线向量。如图所示: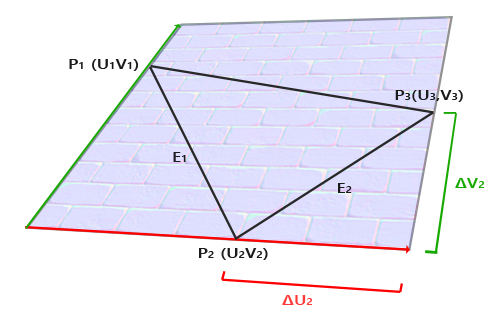
切线向量 T 和副切线向量与纹理坐标的差 方向相同,于是我们可以求解得出 T、B 向量,代码表示如下:
// 顶点位置 | |
glm::vec3 pos1(-1.0, 1.0, 0.0); | |
glm::vec3 pos2(-1.0, -1.0, 0.0); | |
glm::vec3 pos3( 1.0, -1.0, 0.0); | |
// UV 坐标 | |
glm::vec2 uv1(0.0, 1.0); | |
glm::vec2 uv2(0.0, 0.0); | |
glm::vec2 uv3(1.0, 0.0); | |
// 顶点位置 | |
glm::vec3 pos1(-1.0, 1.0, 0.0); | |
glm::vec3 pos2(-1.0, -1.0, 0.0); | |
glm::vec3 pos3( 1.0, -1.0, 0.0); | |
// UV 坐标 | |
glm::vec2 uv1(0.0, 1.0); | |
glm::vec2 uv2(0.0, 0.0); | |
glm::vec2 uv3(1.0, 0.0); | |
float f = 1.0f / (deltaUV1.x * deltaUV2.y - deltaUV2.x * deltaUV1.y); | |
// 切线计算 | |
tangent.x = f * (deltaUV2.y * edge1.x - deltaUV1.y * edge2.x); | |
tangent.y = f * (deltaUV2.y * edge1.y - deltaUV1.y * edge2.y); | |
tangent.z = f * (deltaUV2.y * edge1.z - deltaUV1.y * edge2.z); | |
// 副切线计算 | |
bitangent.x = f * (-deltaUV2.x * edge1.x + deltaUV1.x * edge2.x); | |
bitangent.y = f * (-deltaUV2.x * edge1.y + deltaUV1.x * edge2.y); | |
bitangent.z = f * (-deltaUV2.x * edge1.z + deltaUV1.x * edge2.z); |
对于用 Assimp 导入的模型,我们可以调用 aiProcess_CalcTangentSpace,提前计算出 T、B 向量:
const aiScene* scene = importer.ReadFile( | |
path, aiProcess_Triangulate | aiProcess_FlipUVs | aiProcess_CalcTangentSpace | |
); | |
// 获取计算出来的切线空间 | |
vector.x = mesh->mTangents[i].x; | |
vector.y = mesh->mTangents[i].y; | |
vector.z = mesh->mTangents[i].z; | |
vertex.Tangent = vector; | |
vector.x = mesh->mBiTangents[i].x; | |
vector.y = mesh->mBiTangents[i].y; | |
vector.z = mesh->mBiTangents[i].z; | |
vertex.BiTangent = vector; |
之后我们利用 Assimp 加载法线贴图,但是 wavefront 的模型格式(.obj)导出的法线贴图有点不一样,Assimp 的 aiTextureType_NORMAL 并不会加载它的法线贴图,而 aiTextureType_HEIGHT 却能,所以我们经常这样加载它们:
vector normalMaps = loadMaterialTextures(material, aiTextureType_HEIGHT, "texture_normal"); |
为让法线贴图工作,我们先得在着色器中创建一个 TBN 矩阵。我们先将前面计算出来的切线和副切线向量传给顶点着色器,作为它的属性:
#version 330 core | |
layout (location = 0) in vec3 position; | |
layout (location = 1) in vec3 normal; | |
layout (location = 2) in vec2 texCoords; | |
layout (location = 3) in vec3 tangent; | |
layout (location = 4) in vec3 bitangent; | |
... | |
void main() | |
{ | |
[...] | |
vec3 T = normalize(vec3(model * vec4(tangent, 0.0))); | |
vec3 B = normalize(vec3(model * vec4(bitangent, 0.0))); | |
vec3 N = normalize(vec3(model * vec4(normal, 0.0))); | |
mat3 TBN = mat3(T, B, N) | |
} | |
... |
,如果我们希望更精确的话就不要将 TBN 向量乘以 model 矩阵,而是使用法线矩阵,因为我们只关心向量的方向,不关心平移。就像之前对法线向量的变换一样:
Normal = normalize(mat3(transpose(inverse(model))) * aNormal); |
现在我们有了 TBN 矩阵,如果来使用它呢?通常来说有两种方式使用它:
- 我们直接使用 TBN 矩阵,这个矩阵可以把切线坐标空间的向量转换到世界坐标空间。因此我们把它传给片段着色器中,把通过采样得到的法线坐标左乘上 TBN 矩阵,转换到世界坐标空间中,这样所有法线和其他光照变量就在同一个坐标系中了。
l // 像素着色器normal = texture(normalMap, fs_in.TexCoords).rgb;
normal = normalize(normal * 2.0 - 1.0);
normal = normalize(fs_in.TBN * normal);
- 我们也可以使用 TBN 矩阵的逆矩阵,这个矩阵可以把世界坐标空间的向量转换到切线坐标空间。因此我们使用这个矩阵左乘其他光照变量,把他们转换到切线空间,这样法线和其他光照变量再一次在一个坐标系中了。
l // 顶点着色器void main()
{mat3 TBN = transpose(mat3(T, B, N));// 对于单位向量,转置与求逆得到结果一致,转置开销更小。
vec3 lightDir = fs_in.TBN * normalize(lightPos - fs_in.FragPos);
vec3 viewDir = fs_in.TBN * normalize(viewPos - fs_in.FragPos);
[...]
}
第二种方法的好处是我们可以在顶点着色器中就做完这些事情,因为顶点着色器通常比像素着色器运行的少,所以这是一个极佳的优化,是一种更好的实现方式。
# 共享顶点
在更大的网格中,往往具有很多的共享顶点,这些共享顶点的顶点法线是与其相邻的面法线的平均,这样顶点法线将不再与面法线方向相同,所以我们的切线向量 T 和副切线向量 B 便可能和顶点法线向量不再垂直。为了使得 TBN 矩阵仍然是正交矩阵,我们会用施密特正交化的方法,对 TBN 向量进行重正交化。代码如下:
vec3 T = normalize(vec3(model * vec4(tangent, 0.0))); | |
vec3 N = normalize(vec3(model * vec4(normal, 0.0))); | |
// re-orthogonalize T with respect to N | |
T = normalize(T - dot(T, N) * N); | |
// then retrieve perpendicular vector B with the cross product of T and N | |
vec3 B = cross(T, N); | |
mat3 TBN = mat3(T, B, N) |